
XML Parser 语法分析器简介
语法分析(英:Syntactic analysis,也叫 Parsing)是根据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文本进行分析并确定其语法结构的一种过程。
语法分析器(Parser)通常是作为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。语法分析器通常使用一个独立的词法分析器从输入字符流中分离出一个个的“单词”,并将单词流作为其输入。实际开发中,语法分析器可以手工编写,也可以使用工具(半)自动生成.* wiki
XML语法分析器解析XML文件,并提供其中所载的信息(即Element,Attribute等)并且作进一步处理。
XML语法分析器有两个重要的组成标准。首先是他们验证正确性部分, 第二,提供访问XML文档的接口(SAX或DOM)。这两个组成部分组成的语法分析器很自然有四种可能性,即验证和非验证的SAX解析器和验证和非验证的DOM解析器。
第一条标准,即验证和非验证,这是很容易解释的。一个XML文档是否能被有效检查验证, 是由DTD规范。因此,一个DTD这是绝对必要的。除此之外,良好DTD文档格式也是非常重要的。一个非验证解析器只检查XML文档是否遵循XML规范。在这种情况下,DTD不是必要的, 即使存在也无所谓. 由于一个验证文档分析器是非常耗时,所以应该尽可能避免,所以通常情况下我们用其他方式来验证文档.
第二条标准是通过接口对文件的访问, 即DOM和SAX.
SAX
SAX 的名字是 Simple API for XML, 他是在 XML-DEV Mailing List中诞生的,在1998年5月11日发布1.0版本,SAX是“基于事件”,表示当读到特定的XML结构时候(例如 Element, Attribute等等)就会触发结果,当然在Warning和error的时候也会随之触发相应的结果,开发者可以根据自己定义的事件处理方式独立的输出和处理各种结果。
举个例子
<zitat>
Drum prüfe wer sich ewig bindet, ob sich nicht was Besseres findet.
</zitat>
语法分析器可以触发如下事件
开始Tag
文本
结束Tag
DOM
DOM的名字是Document Object Model,它是由一颗以Element为结点的语法树结构所构成,输出的结果是遍历这颗树的所有结点
<buch>
<titel>Galgenlieder</titel>
<autor>
<vorname>Christian</vorname>
<name>Morgenstern</name>
</autor>
</buch>
结点树结构如下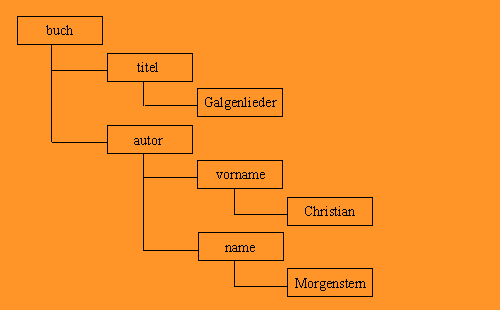
由此可见如果XML文本结构越复杂,构成的树形结构越巨大,相应的所需要的存储空间要比SAX大得多,这也就是DOM-API的缺点所在
对比DOM和SAX
SAX要快速和简单,当然也有很严重的缺点,就是没有对象模型,即没有什么层次结构的存贮关系,所以SAX所应用的领域就是一次性读取文档,从而得到结果
而DOM要慢得多,但是提供了Element之间的树形结果,可以对其进行适当的操作,所以DOM适合交互式的XML文档读取或者XML文档之间存在一些层次关系的梳理方式,但是不要忘记,DOM是需要大量的存贮空间作为支持。